This post builds on the ideas presented in the video and the accompanying paper blog.
TL;DR; A score-based model is built to estimate by using the score function. For any input point in the data space, the model predicts its score, which indicates the direction to higher probability (understanding the score function’s meaning is key). Inference uses Langevin dynamics sampling, iteratively applying the model (ideally many times) to move the input towards higher probability areas, resulting in a final sample from the highest probability area.
Recall that we still have problem on .
Score function
Instead of modeling the density function directly, we model the score function. The score function of a distribution is defined as
Our model aims to estimate this quantity by approximating
an approach known as a score-based model. After that we do some math to get
Note that is independent of the normalizing constant , which is highly advantageous.
Score matching
The score function, , clearly indicates the direction in which the data probability increases, in other words, score function can tell you for any point in your data space in which direction you have to move to get closer to actual data points (probability increase)

In case of images we can start with random Gaussian image and score will tell you which direction we should move to get closer to image manifold (target image).
To do that we just train score-base model to minimize model and the data distribution:
Note: we use Euclidean distance to find distance between two vectors but formula is the same as L2 Norm/Euclidean norm so we can write and we commonly square this distance for (1) Ensure positive values. (2) Penalizes larger differences more. So final formula is then we add expected value (average) to get average across all points with respect to
However, we do not know (the data score) or (the data probability density function). Fortunately, by performing some mathematical derivations, we can eliminate and arrive at the following expression:
we can train minimizing this formula, so both term should be zero:
- means score are 0 or we at a data point.
- gradient of score at the data point is 0 this means it should be a local maximum.
Note: is still requiring in formula, but in practice expectation is average so we can train approximate using sample from (our training data).
So now our goal is to learn a model that given some point in our data space, predict the direction where we should move to get closer to data, this is much easier than learn to predict PDF function, since score function is don’t need the normalizing constant .
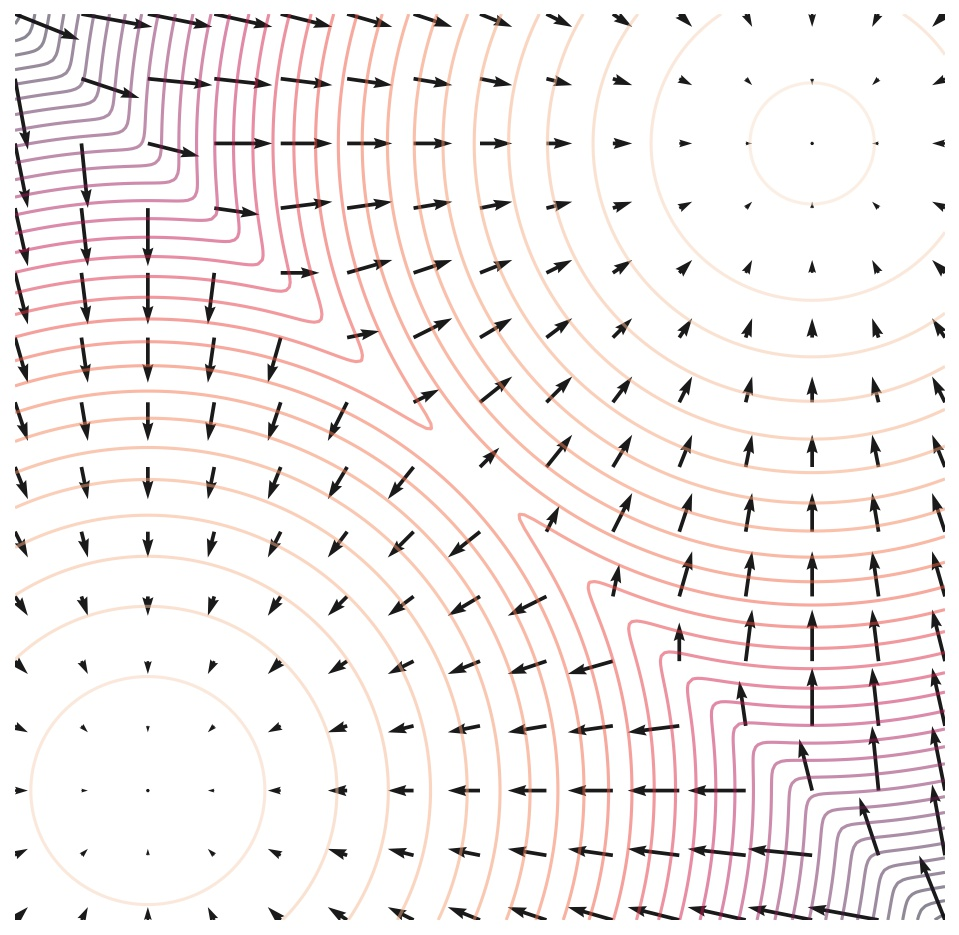
But we ran in to new problems:
- Expensive Training (); When input space is large, you need to compute gradient for each input dimension to do that we need to do backpropagation for all input variable.
- Low Coverage of Data Space (); Our model is not trained on input from the entire space (of course, we train on some data) so when we have input that come from random position outside data space that we trained on, model will be inaccurate in other word model don’t know correct direction, you can see that estimated scores are only accurate in high density regions (score point towards center).
Note: Why is computable (but expensive) while is not computable ? Answer: Integration is total area under the curve so we must compute integral over the entire input of which have high dimensional in other hand differential only take specific point .
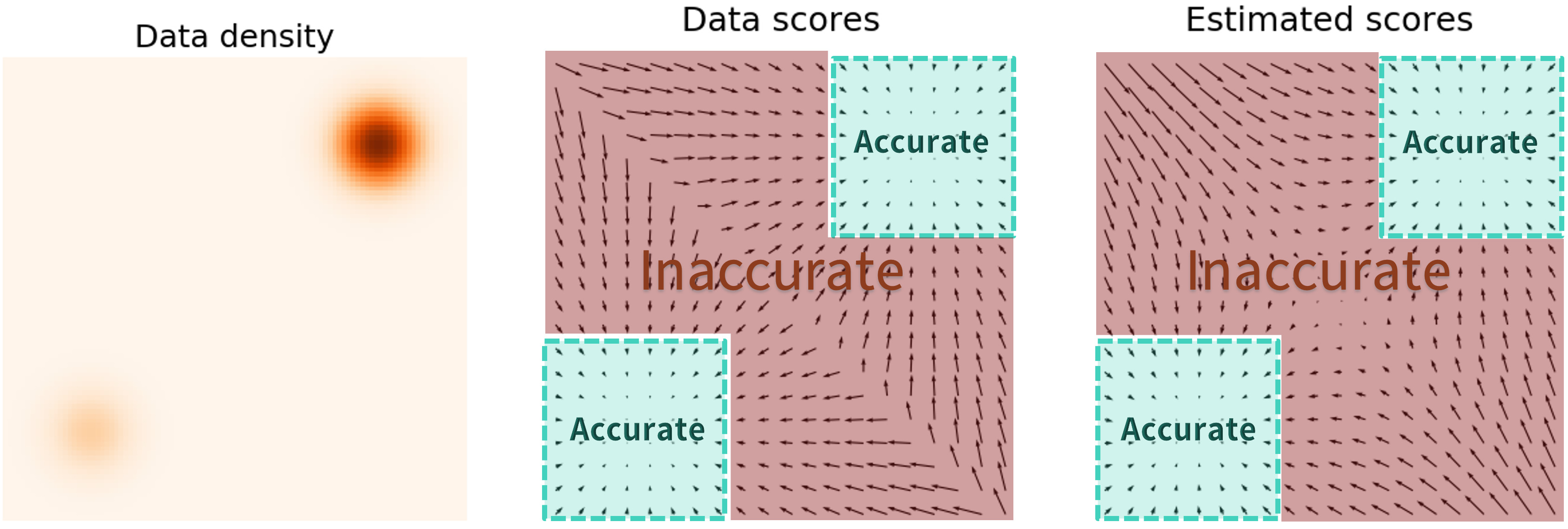
Noise Perturbation
To overcome Low Coverage of Data Space problem; We just add some Gaussian noise to data point
where
Now we denote our pdf as (new noise-perturbed pfd is depending on which is noise level)
and we train Noise Perturbed Objective
here is what happens when we perturb a mixture of two Gaussian perturbed by additional Gaussian noise.

This improve the accuracy of model on low density region, but we still got tradeoff here
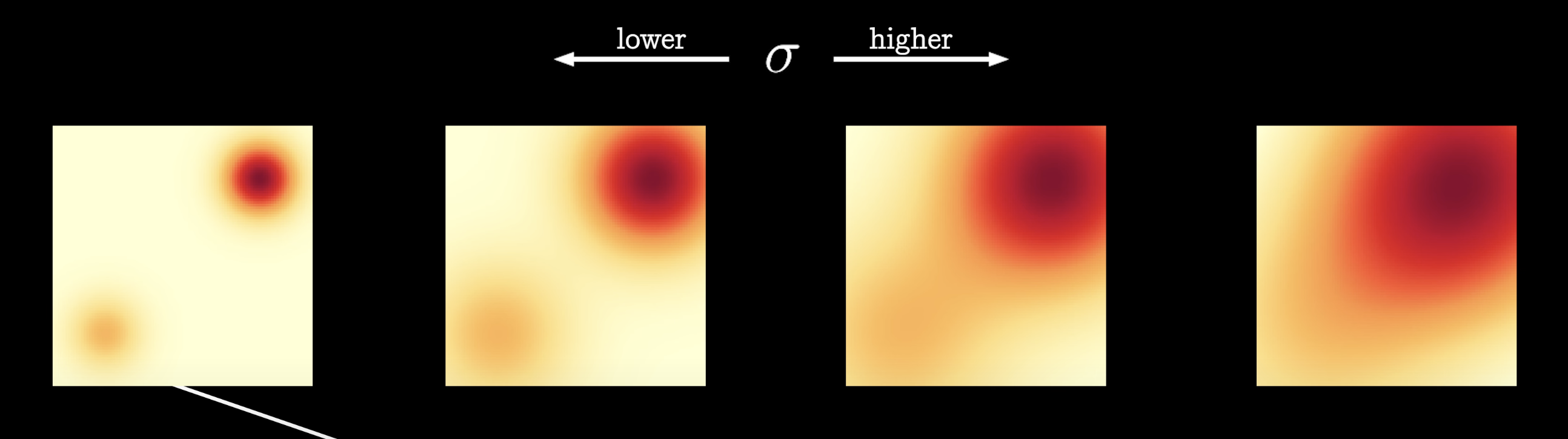
If we use high (more noise):
- Cover more low density regions for better score estimation (resolve Low Coverage of Data Space).
- But it over-corrupts the data and alters it significantly from the original distribution
If we use low (less noise):
- Facing Low Coverage of Data Space problem.
- Not over-corrupts the original data.
Connection to Denoising Autoencoders
someone found the connection between them and can overcome Expensive Training problem by reformulate score-matching objective from
to this:
This is huge, since normally in score-matching objective we don’t know so we can’t compute , we do some math as describe above, and we got Expensive Training problem, but with this new objective we just need to know and we know that in denoising autoencoders!
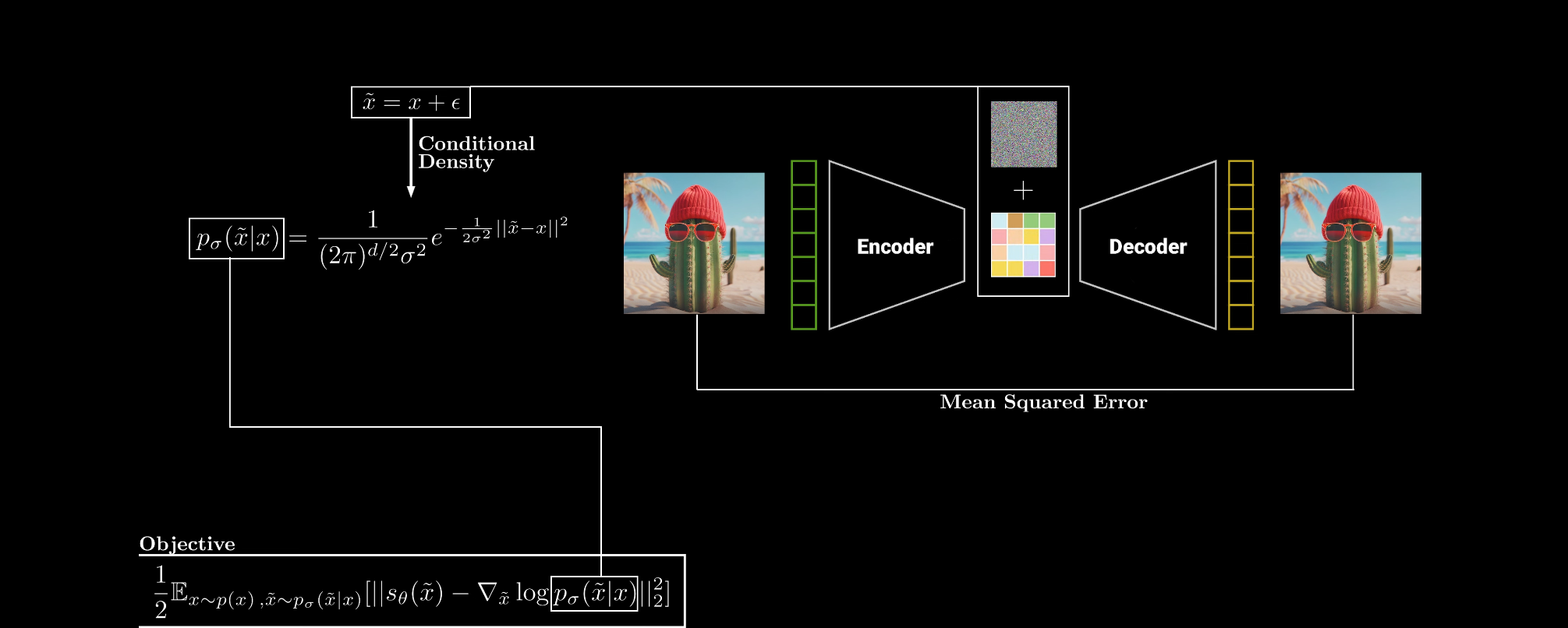
We just need to find by using Multivariate Gaussian distribution then compute and our new objective is to minimize this:
This is beautiful, is noise that we add to input and model need to predict in other word model need to predict direction(score) that back to original data point.

How to generate new sample ?
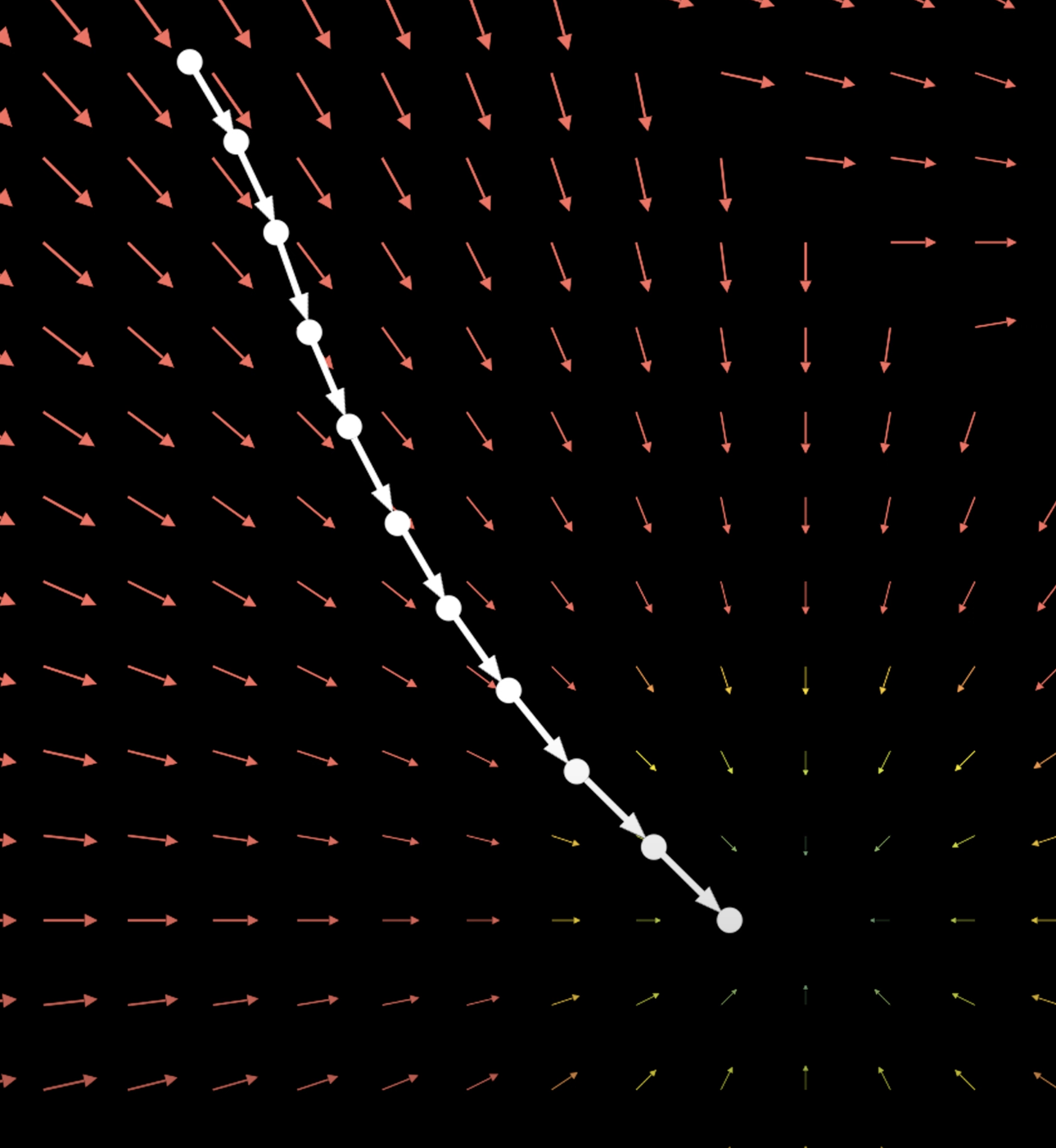
After training our score-based model we can do get denoise sample by iteratively predict new direction using Langevin Dynamics Sampling:
At each step, we update the current sample by adding the product of a small step size and the estimated score . We also add the term to introduce noise, which prevents all samples from collapsing to a single point. So our sample will become closer to data manifold.
Multiple Noise Perturbation
Recall that in Low Coverage of Data Space problem we have tradeoff when select , to achieve the best of both worlds, we use multiple scales of noise perturbations simultaneously.
We start from pre-specify between which have total length with increasing standard deviations now got:
where
now is difference noise, and we add those noise as model input to give more information to model
and jointly train model for all noises
After model is trained, we can use same sample technique except we start with the largest noise since we know that large noise help model in low density region, This method is called annealed Langevin dynamics, also model that trained on difference noised scales is called Noise Conditional Score Networks (NCSNs).
In first paper they use 1000 noise scales.
Link to Stochastic Process
How score-matching link to SDEs
In Multiple Noise Perturbation we use 1000 scales but If we want to cover as much noise scale as possible like 0.001 very small scale to very large scale like we no longer can write as discrete scale anymore (i.e., 1, 2, …, 1000 scales) it will be much better If we turn into function of time where is time that control noise added to image (like control scale), so is also known as Stochastic Process, how?
- We start at our added noise data:
- Compare to SDEs equation
- You can see that change in is just by adding noise in other word change in only influence by stochastic term. We can write SDEs as:
- We know that stochastic term (noise that we add) is only change with time so we can remove input . Now we can write SDEs as:
- If we got forward SDE, we can get reverse SDE:
you can see that it use score function to reverse
Note that in many diffusion model will have technique to add noise differently, so detail in above step is not exactly the same, but idea and step is the same.

This method offers several advantages over using multiple discrete noise levels:
- Continuous noise handling
- Improved generalization
- More accurate score estimation
- Better sampling through continuous annealing
- Flexibility in designing the noise schedule
- Closer connection to the underlying data distribution
Summary
Score-function
The score function, by definition, gives you the gradient of the log probability density function at a given point. In other words, it tells you the direction in which the data density increases most steeply. Using just the score function, you can:
- Guide Sampling:
By following the gradient directions (e.g., via Langevin dynamics), you can iteratively refine a random noise input into a sample that resembles data drawn from the target distribution. - Denoising:
In tasks like denoising, the score function indicates how to adjust a noisy input to move it toward higher probability regions, effectively “cleaning” the data. - Solve Inverse Problems:
The gradient information can be used to guide optimization processes to recover or reconstruct signals from corrupted or incomplete data.
They can be applied to both audio and images
Example Image Generation
Code for this example.
If we want to generate image (new sample), we all know that score-function alone only give direction at given point, so we need to do sampling to make new sample before we link to SDE we use Langevin Dynamics Sampling but after we link to SDE we can use reverse SDE instead.
Steps:
- Define how we perturb our data (add noise to sample), in this example we use
- Define forward SDE from step (1) using forward SDE formula. In this case we got
- Solve forward SDE to get conditional probability, which will be plug into loss function later.
- Plug conditional probability from step (2) into loss function.
- Train score-based model using loss from (4).
- After trained model, we create new sample (image) using these methods.
Other diffusion paper (e.g. DDPM, DDIM) design step (1) differently.
New loss function
Recall this loss function.
this loss only use one noise level , from this section we learned that we need to train with multiple noise and this link to SDEs, so loss become
These are changes:
- Replace with stochastic process : means noisy image at time while is original image.
- Replacing fixed with time : becomes the parameter controlling the noise level range from 0 (original image) to (noisy image). (recall this image)
- Making noise distribution time-dependent: becomes .
- Making the score model time-dependent: becomes .
- Averaging the loss over different times (noise levels): Introducing
- Weighting function : Added to solve this problem
Build Time-Dependent Score-Based Model
Can be any architecture as long as input and output have same dimension, but effective one is U-net. Our model ideally produces so, input is (image) and (time or noise level) but how can we make model understand ?
Recall from link to SDEs section we know that is time in stochastic process which as increase noise added to image, to make model understand time the easiest way is just adding to every intermediate layer in U-net, but
- we can’t code time as
0,1,2,..T, since is continuous in - we can’t add single integer like
0,1,...,Twe must represent time as vector instead, since neural network won’t learn much from single integer.
To solve these problems we must create projection function that can map any time (continuous) to higher dimension vector so we can add this vector to U-net, and it can learn time information, but what projection function we should use ?
To create such a projection function we must do like this:
- In order to convert 1D time to high-dimension
- Create fixed random N-dimension vector.
- We can multiply any time with that vector.
- We will get vector that represent time , difference will always have difference vector.
- From (1) is just linear function this is not enough, since time can be complex and nonlinear. We further use Fourier features which is better to capture complex function, it is crucial that they are designed to be sufficiently expressive to encode the temporal information effectively.
- what I mean is our projection function return where is vector from (1).
Note: Projection means mapping data into a new space.
Lastly we normalize output of network by reason here.
Create new sample
Recall that for any SDE of the form
the reverse-time SDE is given by
Since we have chosen the forward SDE to be
The reverse-time SDE is given by
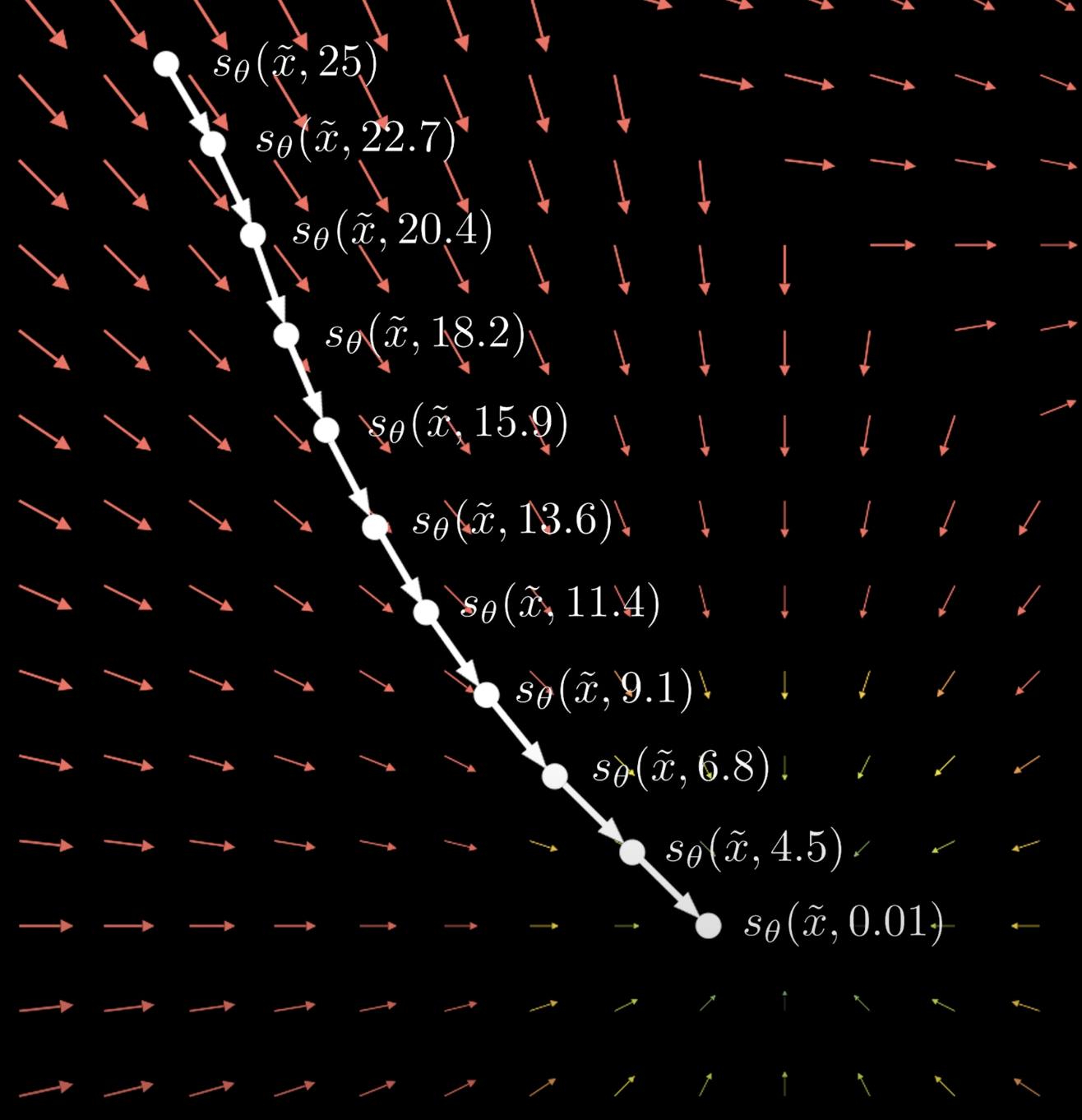
To sample from our time-dependent score-based model , we first draw a sample from the prior distribution , and then solve the reverse-time SDE with numerical methods.
1. Sampling with Numerical SDE Solvers (Euler–Maruyama)
For an SDE of the form
the Euler–Maruyama update rule is
where is a sample from a standard normal distribution, In the context of the reverse-time SDE, the method approximates
with the discretized iteration:
- is the estimated score function.
- is the diffusion coefficient.
- is the time step.
- is Gaussian noise.
We can loop this to generate new sample
2. Sampling with Predictor-Corrector Methods
We combine Predictor (Euler–Maruyama) with Corrector (Langevin MCMC). Recall the classical Langevin MCMC update is given by
but instead of try to get next time step from this, we refine current time step and use Euler–Maruyama to get next time step instead, so Corrector update is
this is detail of how to select step size , then after we refine using Corrector, we use Predictor to get next time step. In summary:
- Refines the sample using Langevin MCMC (corrector step) to reduce discretization error.
- Propagates the refined sample using an Euler–Maruyama update (predictor step).
3. Sampling with Numerical ODE Solvers
In this paper they found that, For any Forward SDE of the form
and have Reverse SDE:
It turns out that Reverse SDE have an associated ODE
which is known as the probability flow ODE. Despite being deterministic (i.e., without the random noise term), this ODE has trajectories whose marginal distributions match those of the original SDE. This means that if you solve this ODE from time to , starting with a sample from , you’ll obtain a sample from (typically the data distribution).
Below is a schematic figure showing how trajectories from this probability flow ODE differ from SDE trajectories, while still sampling from the same distribution.
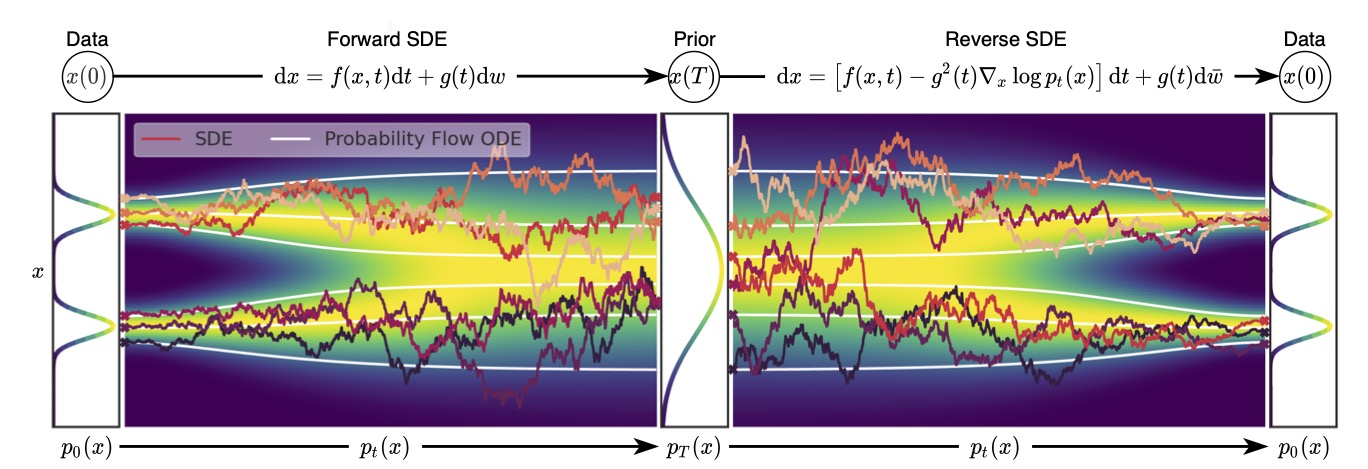
Therefore, we can start from a sample from , integrate the ODE in the reverse time direction, and then get a sample from . In particular, for the SDE in our running example, we can integrate the following ODE from to for sample generation