This is core component of transformer.
Overview
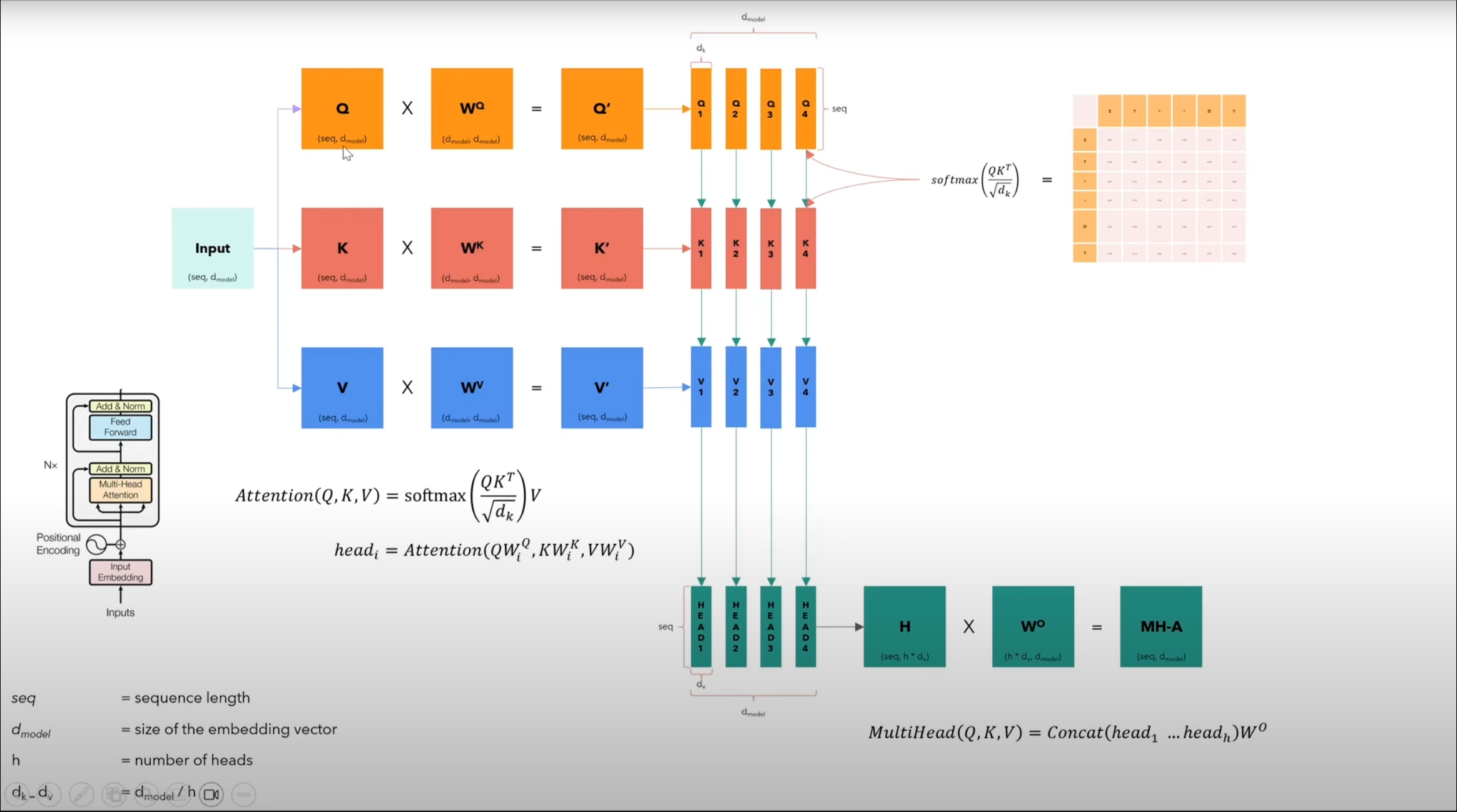
Multi-head attention divides the model dimension (, , ) by the number of heads, applies attention independently to each head, concatenates the results, and finally applies a learned linear transformation () to produce the final output.
Why Multiple Heads?
Input sequences contain various types of relationships and patterns:
- Head 1 might capture grammatical structure
- Head 2 might focus on semantic relationships
- Deeper heads might learn more complex, abstract patterns
The final learned parameter combines and refines these different aspects into a coherent representation, so
Attention Mechanisms
One-Head Attention
Components and Dimensions
| Component | Shape | Description |
|---|---|---|
| Query (Q) | (seq_length, d_model) | Input sequence transformation |
| Key (K) | (seq_length, d_model) | Used to compute attention scores |
| Value (V) | (seq_length, d_model) | Used to compute final output |
Learnable Parameters
| Parameter | Shape | Purpose |
|---|---|---|
| (d_model, d_model) | Query transformation | |
| (d_model, d_model) | Key transformation | |
| (d_model, d_model) | Value transformation |
Attention formula
Process Steps
- Apply linear transformation to get .
- Do dot product of and .
- For self-attention: Think of this like find attention score or find ideas, relation within input sequence (e.g. gramma, abstract ideas, we hope fully model learn something complex as we going deeper(more heads))
- For cross-attention: similar to self-attention except we and are form difference sequence like in translation task, so this is like find attention score from both sequence (e.g. ideas of how we translate Thai to English)
- Divide by : Just for numerical stability.
- Apply
softmax, so :- Converts attention scores into probabilities (values between 0 and 1)
- Do dot product of and :
- Think of this like after we know ideas, relation for each word (attention score ) then what exactly should we added to the embedding to make some reflection, so this is like dot product with to make new representations
- Now we got new representations for all word that can be add to original words (in Add&Norm layer), so we can get better, more meaningful words.
Practical Example
Consider the sequence “A blue cat”, word “cat” embedding is then model compute self-attention, start with and now model know attention score or an ideas that is this cat is a weird blue cat then model compute to get new vector that reflect this knowledge , now we (done in Add&Norm) , so we get new that change meaning from “cat” to “blue cat”.
| meaning before | meaning after |
|---|---|
 |  |
Masking Types
Decoder Self-Attention Masking (causal mask)
[ 1 0 0 ] # First position can only look at itself
[ 1 1 0 ] # Second position can look at first and itself
[ 1 1 1 ] # Third position can look at everything up to itself- When compute , sets upper triangle to
-infbeforesoftmax - Prevents model from seeing future tokens during training
- Essential for autoregressive generation
Padding Masking
[ 1 1 1 0 0 ]
[ 1 1 1 0 0 ]
[ 1 1 1 0 0 ]- Applied to both encoder and decoder
- Masks padding tokens to prevent them from contributing to attention